
In the rapidly evolving field of artificial intelligence, large language models (LLMs) have emerged as powerful tools for various applications. One of the most exciting developments in this area is the DeepSeek-R1-Zero model, which leverages reinforcement learning (RL) to enhance reasoning capabilities without relying on supervised fine-tuning (SFT). This blog post will guide you through the intricacies of DeepSeek-R1-Zero, from a beginner’s perspective to more advanced technical details.
Introduction to DeepSeek-R1-Zero
DeepSeek-R1-Zero is a groundbreaking model designed to improve the reasoning abilities of LLMs through pure reinforcement learning. Unlike traditional models that require supervised fine-tuning, DeepSeek-R1-Zero skips this step, allowing it to develop reasoning skills autonomously. This approach not only saves computational resources but also provides insights into how models can learn complex problem-solving strategies from scratch.
Understanding Reinforcement Learning in DeepSeek-R1-Zero
What is Reinforcement Learning?
Reinforcement learning is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative reward. In the context of DeepSeek-R1-Zero, the model learns to generate better reasoning outputs by optimizing a policy model through an RL algorithm called Group Relative Policy Optimization (GRPO).
Group Relative Policy Optimization (GRPO)
GRPO is the backbone of DeepSeek-R1-Zero’s learning process. It optimizes the policy model, denoted as
Objective Function
The objective function,
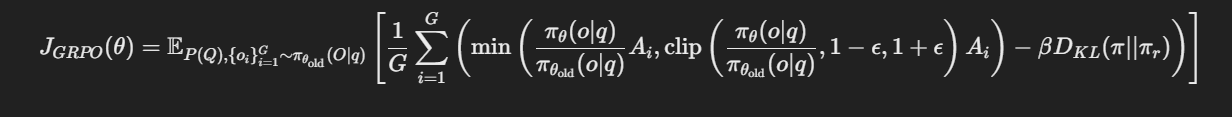
To ensure the equation renders correctly, let’s break it down:
-
Expectation and Sampling:
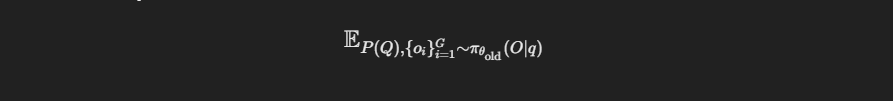
-
Summation and Minimization:
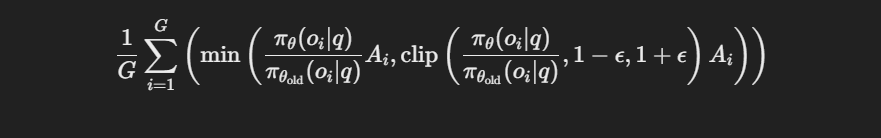
-
KL Divergence Term:
- E is the expectation over the distribution of questions
Sampling Outputs
For each question
Advantage Calculation
The advantage
The advantage quantifies how much better a particular output is compared to the average output in the group, in terms of the reward. It is normalized by the standard deviation to ensure the stability of learning.
Policy Optimization
The policy model
Reward System
The reward system provides feedback to the model, indicating the quality of its outputs. DeepSeek-R1-Zero uses a rule-based reward system that consists of two types of rewards:
- Accuracy Rewards: These rewards are given when the model provides correct answers. For math problems, the final answer must be in a specified format to allow for automated verification. For coding problems, the correctness of the code is checked using a compiler.
- Format Rewards: These rewards are used to incentivize the model to structure its responses with the reasoning process enclosed between
and tags. This promotes a consistent structure for the model’s outputs, which can help with interpretability.
Baseline Estimation
Unlike traditional RL algorithms that utilize a critic model to estimate the baseline, GRPO estimates the baseline directly from group scores. This method avoids the use of a large critic model, saving computational resources during training.
Training and Self-Evolution Process
Training Template
To guide the model, a simple template is used. This template instructs the model to first produce a reasoning process and then provide the final answer. The model is not given any specific instructions on how to reason, allowing researchers to observe its natural development through the RL process.
Self-Evolution
As the RL training progresses, DeepSeek-R1-Zero shows consistent improvement in performance. For example, its average pass@1 score on the AIME 2024 benchmark increases from 15.6% to 71.0%. The model learns to spend more time thinking and increases the length of its reasoning process. It develops sophisticated behaviors such as reflection and exploring alternative problem-solving approaches, which emerge through interaction with the RL environment.
Aha Moment
During training, the model experiences an “aha moment” where it learns to rethink its initial approach by allocating more thinking time to the problem. This moment demonstrates the model’s ability to learn advanced problem-solving strategies autonomously through RL.
Key Achievements
- Autonomous Learning: DeepSeek-R1-Zero demonstrates that LLMs can develop reasoning skills through pure RL without any supervised data.
- Strong Reasoning Capabilities: The model achieves performance levels comparable to OpenAI-o1-0912 on certain benchmarks.
- Majority Voting: Using majority voting, its performance on AIME 2024 further improves, exceeding the performance of OpenAI-o1-0912.
Limitations
Despite its impressive capabilities, DeepSeek-R1-Zero faces issues like poor readability and language mixing. Its responses may not always be in a human-friendly format and might include multiple languages in one answer.
Conclusion
DeepSeek-R1-Zero is a revolutionary model that learns to reason through pure reinforcement learning, without any prior training on reasoning tasks. It demonstrates the power of RL to enable models to develop complex problem-solving skills and improve their performance over time. While it has some limitations, the insights gained from DeepSeek-R1-Zero pave the way for future advancements in the field of large language models.
For more you can check out this page. Rejection Sampling in DeepSeek-R1